Hey everyone, I’m currently working through a great tutorial series on youtube for ROS2. Unfortunately, I ran into a bit of an issue with a race condition in a launch file. The controller managers were timing out before Gazebo was able to launch.
Controller manager not available
The author offers a suggestion to try using OnProcessExit to work around this but unfortunately it did not work for me. The comments on the video seem to suggest that a few others also hit this problem.
I did a bit of Googling and found an alternative way to add a delay on startup using TimerAction. Using the following code as a replacement for the original launch actions seems to work:
import os
from ament_index_python.packages import get_package_share_directory
from launch import LaunchDescription
from launch.actions import IncludeLaunchDescription
from launch.actions import TimerAction
from launch.launch_description_sources import PythonLaunchDescriptionSource
from launch.actions import RegisterEventHandler
from launch.event_handlers import OnProcessExit
from launch_ros.actions import Node
def generate_launch_description():
# Include the robot_state_publisher launch file, provided by our own package. Force sim time to be enabled
# !!! MAKE SURE YOU SET THE PACKAGE NAME CORRECTLY !!!
package_name='my_bot' #<--- CHANGE ME
rsp = IncludeLaunchDescription(
PythonLaunchDescriptionSource([os.path.join(
get_package_share_directory(package_name),'launch','rsp.launch.py'
)]), launch_arguments={'use_sim_time': 'true'}.items()
)
# Include the Gazebo launch file, provided by the gazebo_ros package
gazebo = IncludeLaunchDescription(
PythonLaunchDescriptionSource([os.path.join(
get_package_share_directory('gazebo_ros'), 'launch', 'gazebo.launch.py')]),
)
# Run the spawner node from the gazebo_ros package. The entity name doesn't really matter if you only have a single robot.
spawn_entity = Node(package='gazebo_ros', executable='spawn_entity.py',
arguments=['-topic', 'robot_description',
'-entity', 'my_bot'],
output='screen')
# This helps to address race conditions on startup for the
# controller managers. Note that we are exporting delayed_controller_manager_spawner
# instead of just diff_drive_spawner.
delayed_controller_manager_spawner = TimerAction(
period=10.0,
actions=[
Node(
package="controller_manager",
executable="spawner.py",
arguments=["diff_cont"],
),
Node(
package="controller_manager",
executable="spawner.py",
arguments=["joint_broad"],
)
],
)
# Launch them all!
return LaunchDescription([
rsp,
gazebo,
spawn_entity,
delayed_controller_manager_spawner,
])
I ran into a bit of an issue with a RaspberryPi 4 running Ubuntu 20.04.5 this morning. Running vcgencmd get_camera should have returned supported=1 detected=1 but instead I was getting supported=0 detected=0.
This was a bit of a hard one to track down with Google but I eventually came across a stackoverflow post suggesting the following:
If you’re using a new camera you may also run into this error:
mmal: Cannot read camera info, keeping the defaults for OV5647
mmal: mmal_vc_component_create: failed to create component 'vc.ril.camera' (1:ENOMEM)
mmal: mmal_component_create_core: could not create component 'vc.ril.camera' (1)
mmal: Failed to create camera component
mmal: main: Failed to create camera component
mmal: Only 76M of gpu_mem is configured. Try running "sudo raspi-config" and ensure that "memory_split" has a value of 128 or greater
The fix for this one is to simply append another line to /boot/firmware/config.txt. All you’ll need is gpu_mem=128.
Another issue you might run into is VHCI initialization failed. Generally, that just means you need to add your current user to the video group.
# Check your current user's groups.
groups
# Add your user to the video group.
sudo usermod -aG video <username>
Once you’ve added the group, rebooting should be enough to get past that error.
I’m currently following a tutorial to simulate a fairly basic lidar robot with ROS2 and Gazebo: https://www.youtube.com/watch?v=laWn7_cj434. Unfortunately, there have been a few updates since the tutorial was created and a number of the commands don’t map 1:1 (no copy and paste).
While trying to create a launch file I ran into the following error:
[create-3] [ERROR] [1668289712.483268807] [ros_gz_sim]: Request to create entity from service [/world/deafult/create] timed out.
This was the relevant line in the launch file:
# Run the spawner node from the gazebo_ros package. The entity name doesn't really matter if you only have a single robot. spawn_entity = Node(package='ros_ign_gazebo', executable='create', arguments=[ '-world', 'deafult', '-topic', 'robot_description', '-entity', 'my_bot'], output='screen')
The issue causing it to hang is that the world doesn’t exist. In my case, it’s because of a typo. However, if you’ve defined a world that you haven’t created yet it will result in the same error.
I’m currently following the ros2 turtlesim tutorial with Ubuntu on an M1 Mac with Parallels and Ubuntu. Unfortunately, I hit a ‘device not found’ when trying to start the control node.
A bit of Googling revealed that 3D acceleration might not be enabled. To fix this, all you need to do is the following:
Open settings in Parallels (the cog icon)
Click the Hardware tab up the top
Click Graphics on the left hand side
Click Advanced
Tick Enable 3D Acceleration
You’ll need to restart the VM, but once that’s done the libgl error should be resolved!
If this doesn’t work, there are a few other things you can check. First, double check that you’ve installed (or re-installed) Parallels Tools.
I have also found that the 3D Acceleration seems to randomly break or reset itself. If it hasn’t automatically unchecked itself, I’ve occasionally had to do the following to get it working again:
Stop the VM
Disable 3D Acceleration
Start the VM
Stop the VM
Enable 3D Acceleration
Start the VM
Another options mentioned in this thread is to set the following environment variable before starting rviz or gazebo:
I normally use DigitalOcean or Azure for docker and kubernetes but have decided to give AWS a go this time around. I was following a guide on deploying an image to a new ECR repo and hit a couple of issues.
The first was that running the login command output help options instead of the password I was expecting:
aws ecr get-login --no-include-email --region us-east-2
usage: aws [options] <command> <subcommand> [<subcommand> ...] [parameters]
To see help text, you can run:
aws help
aws <command> help
aws <command> <subcommand> help
aws: error: argument operation: Invalid choice, valid choices are:
batch-check-layer-availability | batch-delete-image
batch-get-image | batch-get-repository-scanning-configuration
complete-layer-upload | create-pull-through-cache-rule
create-repository | delete-lifecycle-policy
delete-pull-through-cache-rule | delete-registry-policy
delete-repository | delete-repository-policy
describe-image-replication-status | describe-image-scan-findings
describe-images | describe-pull-through-cache-rules
...
This turned out to be an issue because the command had been deprecated. Instead, use the following:
The second issue I ran into was an error while trying to run the new command:
An error occurred (AccessDeniedException) when calling the GetAuthorizationToken operation: User: arn:aws:iam::<ACCOUNT_ID>:user/<USER> is not authorized to perform: ecr:GetAuthorizationToken on resource: * because no identity-based policy allows the ecr:GetAuthorizationToken action
Adding the following role to my user resolved the issue: AmazonEC2ContainerRegistryPowerUser
Once I was passed this, I hit another issue using the command from the github link above:
Error response from daemon: login attempt to https://<ACCOUNT_ID>.dkr.ecr.us-east-2.amazonaws.com/v2/ failed with status: 400 Bad Request
This took a bit of digging, but eventually I came across a thread where someone was using the same command and had hit the same issue. Adding the region to the get-login-password call seemed to fix it:
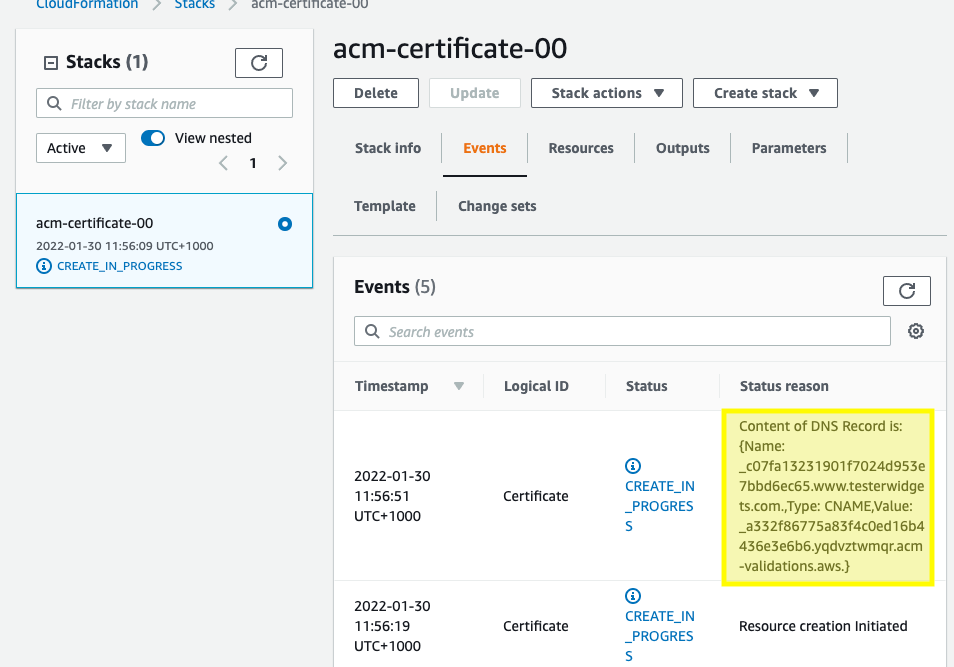
I ran into a bit of an issue today while creating a certificate with CloudFormation. After kicking the stack off it ended up hanging on a step to create a domain verification entry in Route 53.
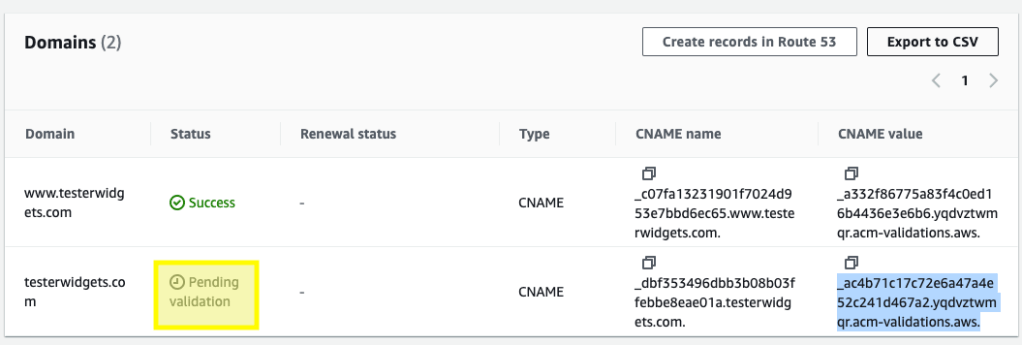
I had used this script multiple times for creating a certificate for a subdomain, but this time I included an apex domain as well. In order to narrow things down a little further I checked out the certificate via the console:
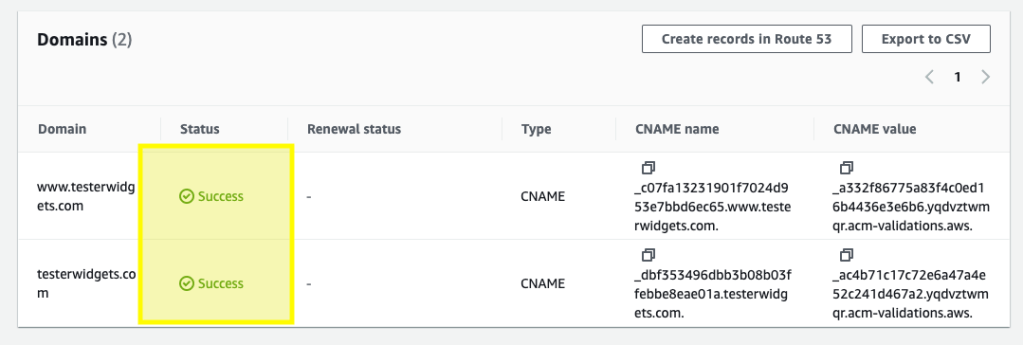
While the subdomain had passed the apex domain was still sitting in pending. Surprisingly, in Route53 the record DID exist. In order to get things moving again I manually deleted the record and then clicked “Create records in Route 53”.
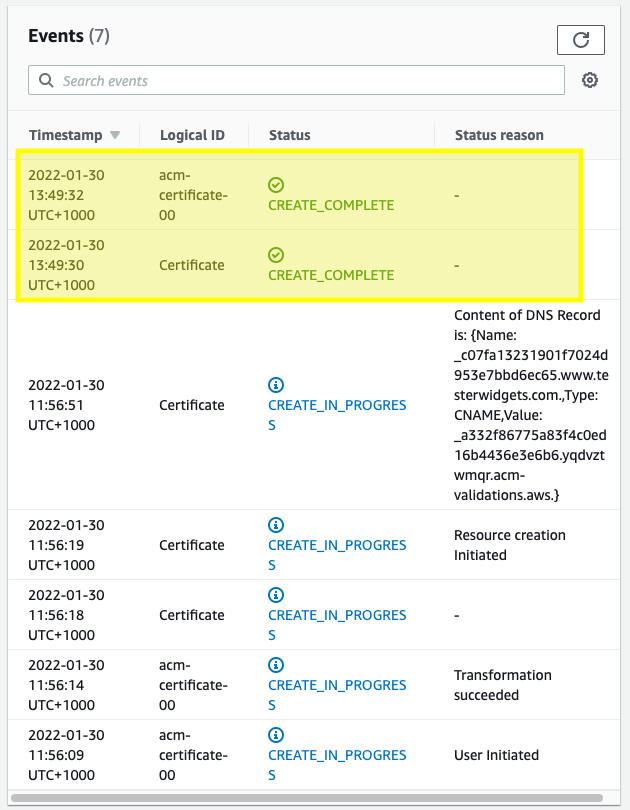
This re-created the record I’d just deleted, and after a couple of minutes the domain validation passed and then the certificate was created:
This was a bit of a weird one that I have been unable to reproduce. I’m not certain why the DNS validation ended up hanging but retriggering the process seems to have resolved it.
Note that there are other legitimate reasons why your deployment might be hanging at this step:
When you use the AWS::CertificateManager::Certificate resource in a CloudFormation stack, domain validation is handled automatically if all three of the following are true: The certificate domain is hosted in Amazon Route 53, the domain resides in your AWS account, and you are using DNS validation.
However, if the certificate uses email validation, or if the domain is not hosted in Route 53, then the stack will remain in the CREATE_IN_PROGRESS state. Further stack operations are delayed until you validate the certificate request, either by acting upon the instructions in the validation email, or by adding a CNAME record to your DNS configuration. For more information, see Option 1: DNS Validation and Option 2: Email Validation.
If you’re like me and a bit slack with your personal projects you might’ve started receiving the following error today:
admin@Admins-iMac ui % git push
remote: Support for password authentication was removed on August 13, 2021. Please use a personal access token instead.
remote: Please see https://github.blog/2020-12-15-token-authentication-requirements-for-git-operations/ for more information.
fatal: unable to access 'https://github.com/Buzzology/referrer.git/': The requested URL returned error: 403
As the message says, Github wants you to start using a Personal Access Token (PAT) instead of password authentication. Luckily, the fix is pretty straight forward – you’ll need to create a Personal Access Token and then update your keychain.
Once you’re on the Personal Access Tokens page you should see something like the following:
Click the Generate new token button, set an expiry and then copy the generated value (you’ll need it in the next step).
Step #2: Updating your keychain
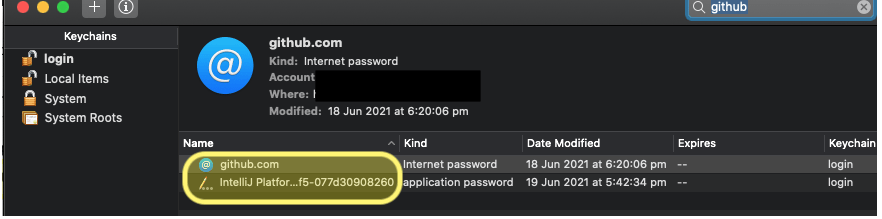
Now that you’ve got your Personal Access Token you need to replace the password that you’ve currently got stored in your keychain. To start, open search and bring up Keychain Access:
If you’ve got quite a few keys there you can filter them by searching for github. You’ll then need to double click on each of the entries and replace the stored password with your personal access token:
Note that you’ll first need to click Show Password.
Now that your keychain is updated, close and then re-open any of your terminals and you should be good to go.
admin@Admins-iMac ui % git push
Enumerating objects: 110, done.
Counting objects: 100% (110/110), done.
Delta compression using up to 4 threads
Compressing objects: 100% (91/91), done.
Writing objects: 100% (93/93), 15.30 KiB | 2.19 MiB/s, done.
Total 93 (delta 64), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (64/64), completed with 14 local objects.
To https://github.com/Buzzology/referrer.git
0d2ecf0..97f2716 master -> master
admin@Admins-iMac ui %